C++ (Concurrency) Memory Model
Great Presentation:
Memory Model Relations
This is the contract between the programmer and the system. The system consists of the compiler that generates machine code, the processor that executes the machine code and includes the different caches that store the state of the program. Each of the participants wants to optimise its part. The weaker the rules are that the programmer has to follow, the more potential there is for the system to generate a highly optimised executable. The stronger the contract, the fewer liberties for the system to generate an optimised executable.
在多線程的領域中,記憶體模型的關係有幾個名詞值得注意happens-before和 synchronizes-with,以下介紹。
synchronizes-with
The synchronizes-with relationship is something that you can get only between operations on atomic types.
The memory effects of source-level operations – even non-atomic operations – are guaranteed to become visible to other threads.
Such as mutex, it contains atomic types and the operations on that data structure perform the appropriate atomic operations internally. (It doen’t mean std::atomic is implemented in std::mutex)
happens-before
It specifies which operations see the effects of which other operations.
If operation A on one thread inter-thread happens before operation B on another thread, then A happens before B.
Inter-thread happens-before is relatively simple and relies on the synchronizes-with relationship.
If operation A in one thread synchronizes with operation B in another thread, then A inter-thread happens before B.
Inter-thread happens-before also combines with the sequenced-before relation.
If operation A is sequenced before operation B, and operation B inter-thread happens before operation C, then A inter-thread happens before C.
The Synchronisation and Ordering Constraints
Being able to access shared variables safely is not enough to write any non-trivial concurrent program. The key concept we have to remember here is visibility. In reality, the CPU is only changing the content of its cache; the cache and memory hardware eventually propagate these changes to the main memory or the shared higher-level cache, at which point these changes may become visible to other CPUs.
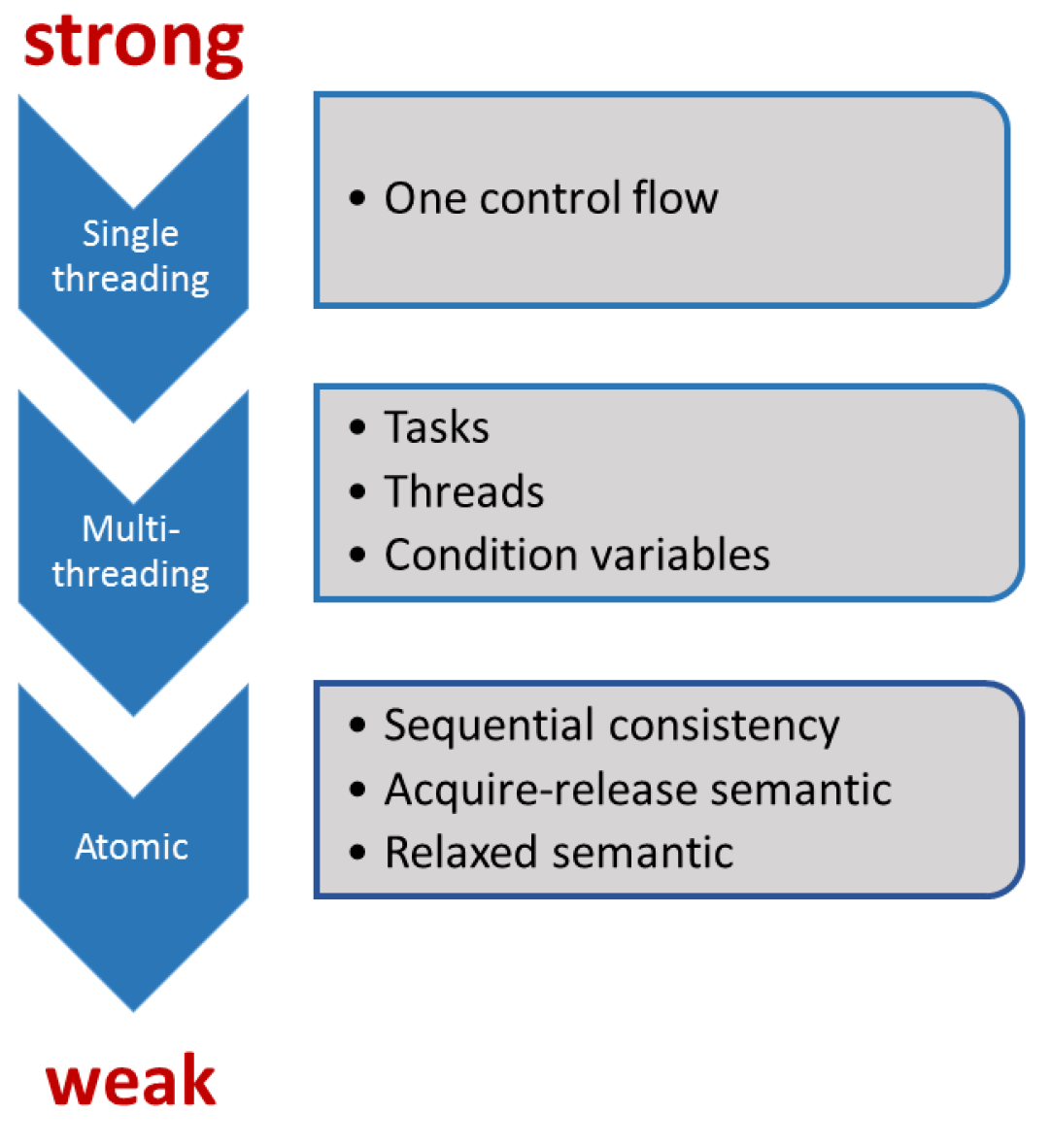
There are six memory ordering options that can be applied to operations on atomic types, they represent 3 models:
- Sequential Consistency:
memory_order_seq_cst - Acquire-release:
memory_order_acquire,memory_order_release,memory_order_acq_rel,memory_order_consume - Relaxed:
memory_order_relaxed
These distinct memory-ordering models can have varying costs on different CPU architectures.
Performance Benefit: Relaxed > Acquire-release > Sequential Consistency
Sequential Consistency
The default ordering is named sequentially consistent because it implies that the behavior of the program is consistent with a simple sequential view of the world. If all operations on instances of atomic types are sequentially consistent, the behavior of a multithreaded program is as if all these operations were performed in some particular sequence by a single thread. The downside is that the system has to synchronise threads.
Note: common x86 and x86-64 architectures offer sequential consistency relatively cheaply
// producerConsumer.cpp
#include <atomic>
#include <iostream>
#include <string>
#include <thread>
std::string work;
std::atomic<bool> ready(false);
void consumer(){
while(!ready.load()){}
std::cout<< work << std::endl;
}
void producer(){
work= "done";
ready=true;
}
int main(){
std::thread prod(producer);
std::thread con(consumer);
prod.join();
con.join();
}
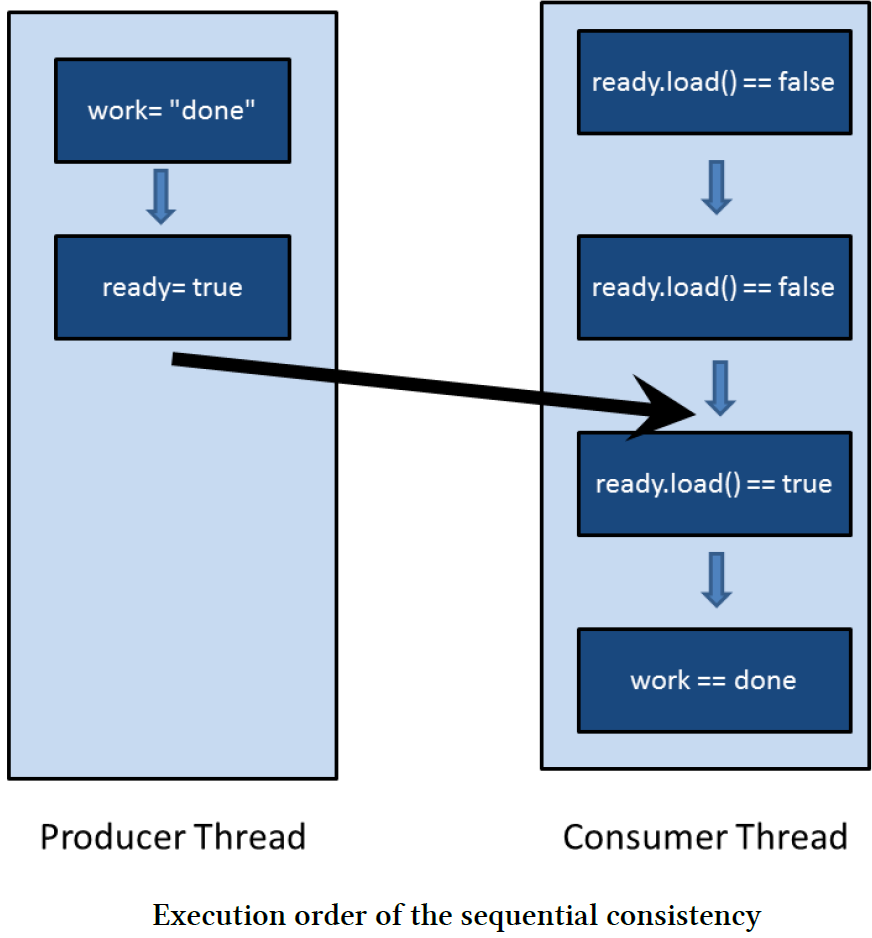
→ work= "done" happens-before ready = true
→ while(!ready.load()){} happens-before std::cout<< work << std::endl
ready = true synchronizes-with while(!ready.load()){}
→ ready = true inter-thread happens-before while (!ready.load()){}
→ ready = true happens-before while (!ready.load()){}
conclusion: work= "done" happens-before ready = true happens-before while(!ready.load()){} happens-before std::cout<< work << std::endl
Another Example:
#include <atomic>
#include <thread>
#include <assert.h>
std::atomic<bool> x,y;
std::atomic<int> z;
void write_x()
{
x.store(true,std::memory_order_seq_cst);
}
void write_y()
{
y.store(true,std::memory_order_seq_cst);
}
void read_x_then_y()
{
while(!x.load(std::memory_order_seq_cst)){}
if(y.load(std::memory_order_seq_cst))
++z;
}
void read_y_then_x()
{
while(!y.load(std::memory_order_seq_cst)){}
if(x.load(std::memory_order_seq_cst))
++z;
}
int main()
{
x=false;
y=false;
z=0;
std::thread a(write_x);
std::thread b(write_y);
std::thread c(read_x_then_y);
std::thread d(read_y_then_x);
a.join();
b.join();
c.join();
d.join();
assert(z.load()!=0);
}
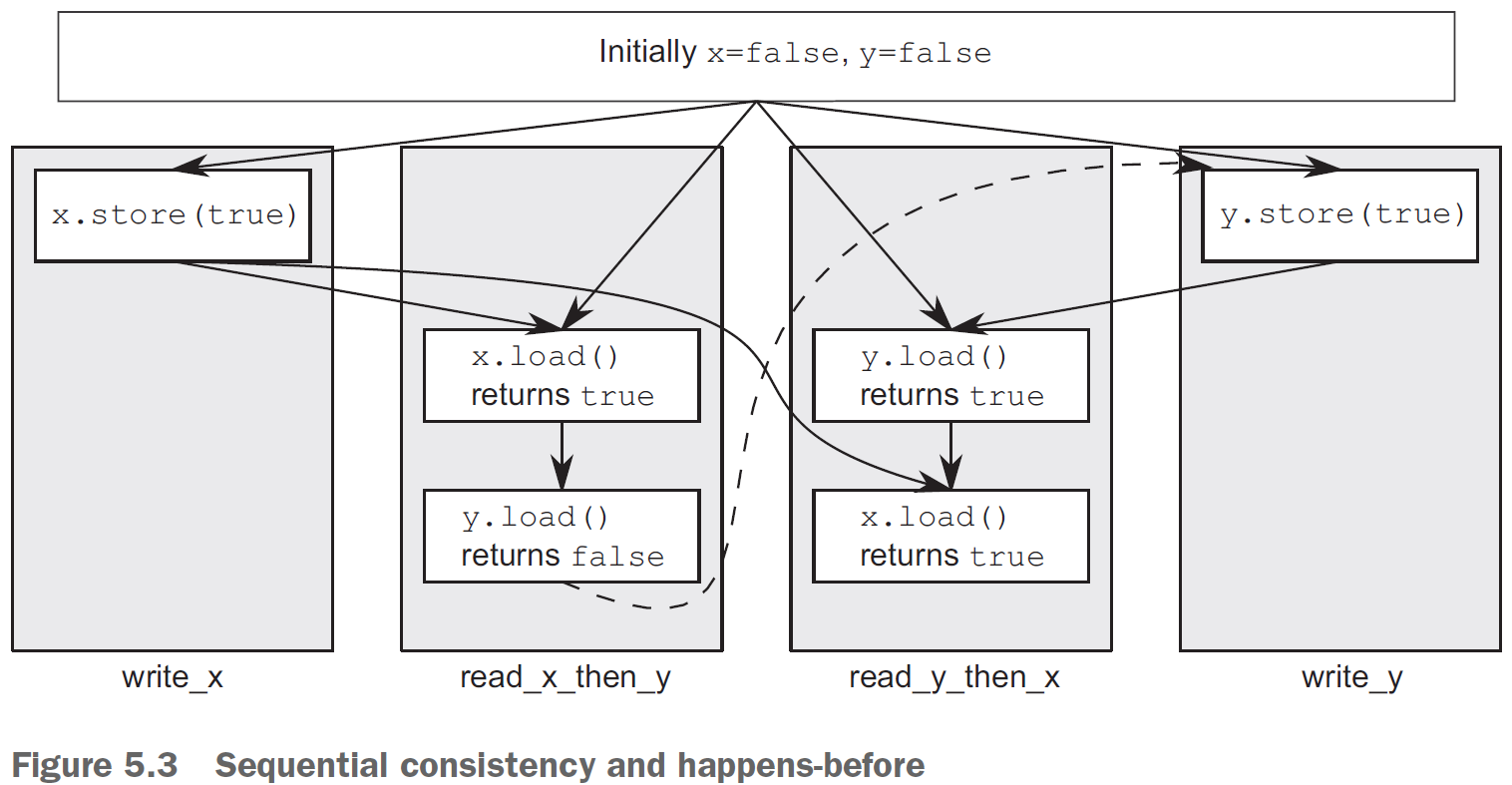
The dashed line from the load of y in read_x_then_y to the store to y in write_y shows the implied ordering relationship required in order to maintain sequential consistency: the load must occur before the store in the global order of memory_order_seq_cst operations in order to achieve the outcomes given here.
Acquire-Release
There is no global synchronisation between threads in the acquire-release semantic; there is only synchronisation between atomic operations on the same atomic variable. A release operation synchronises with an acquire operation on the same atomic and establishes an ordering constraint. For example:
- A write operation on one thread synchronises-with a read operation on another thread on the same atomic variable.
- The releasing of a lock or mutex synchronizes-with the acquiring of a lock or a mutex.
- The completion of the
threadsynchronizes-with thejoin. - The completion of the callable of the
tasksynchronizes-with the call towait or geton thefuture. waitandnotify_onecall on acondition variable
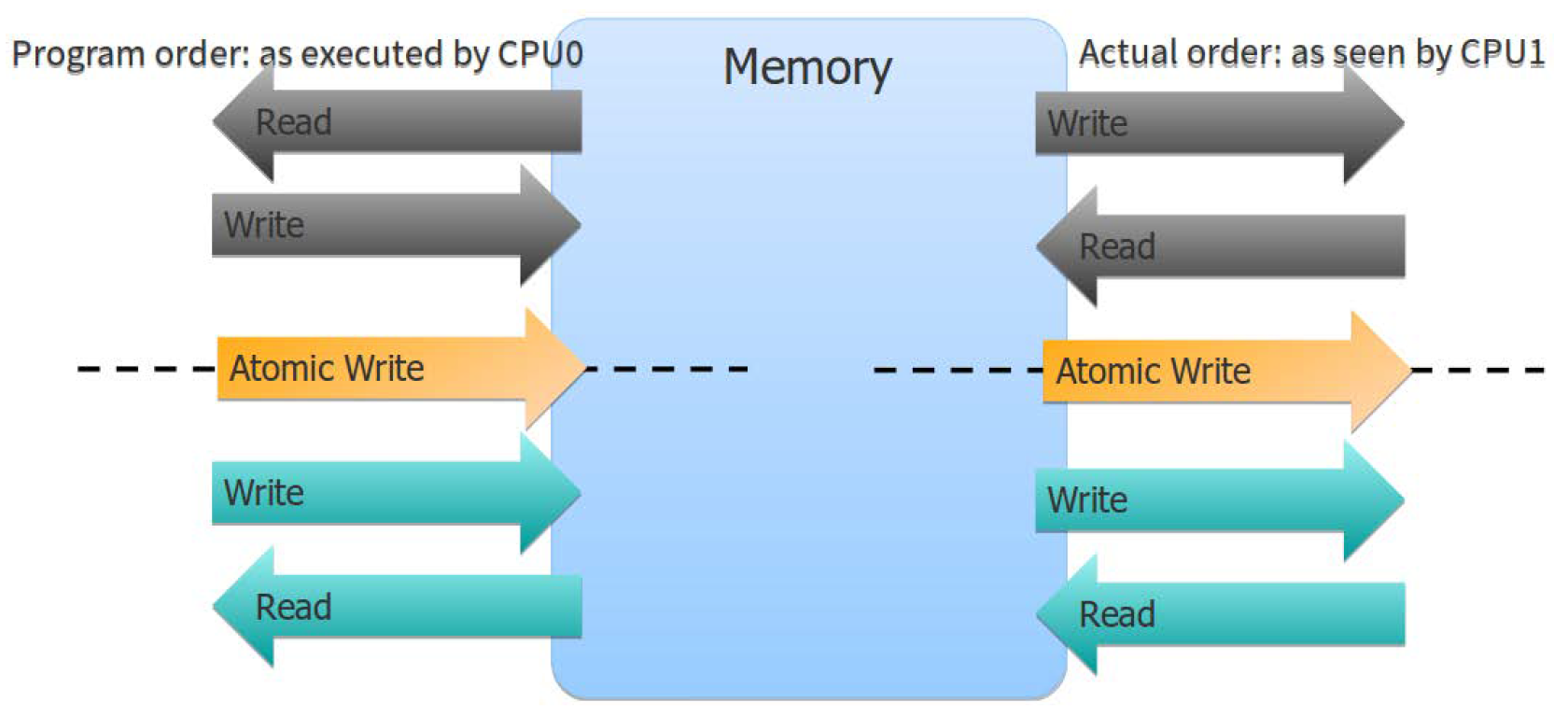
The atomic operations with memory order guarantees act as barriers across which other operations cannot move. You can imagine such a barrier in Figure XXXXX, dividing the entire program into two distinct parts: everything that happened before the count was incremented and everything that happened after. For that reason, it is often convenient to talk about such atomic operations as memory barriers.
Acquire-Release is actually composed of two operation. Release memory order and Acquire memory order.
Release memory order:
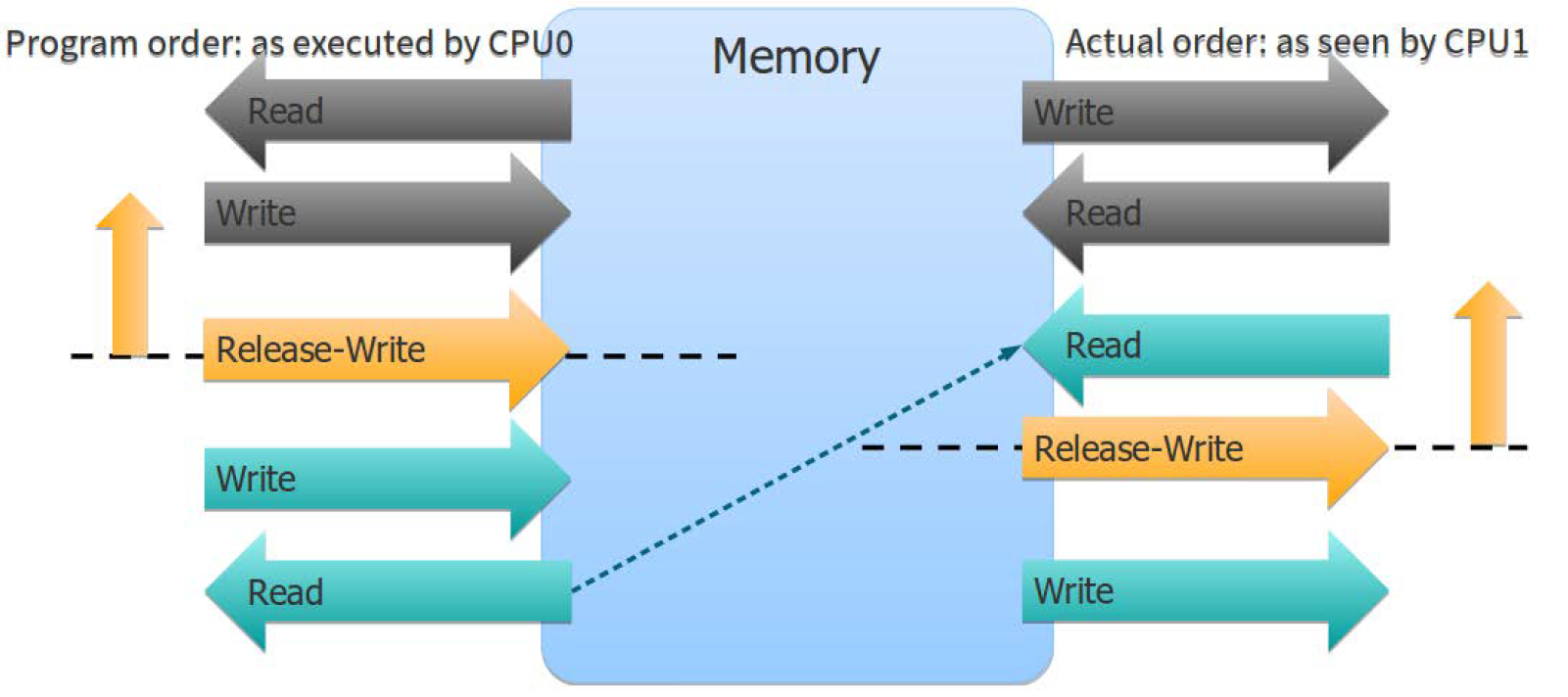
All operations executed before the atomic operation with the barrier must become visible to other threads before they execute the corresponding atomic operation. For this reason, the release memory barrier and the corresponding acquire memory barrier are sometimes called half-barriers.
Acquire memory order:
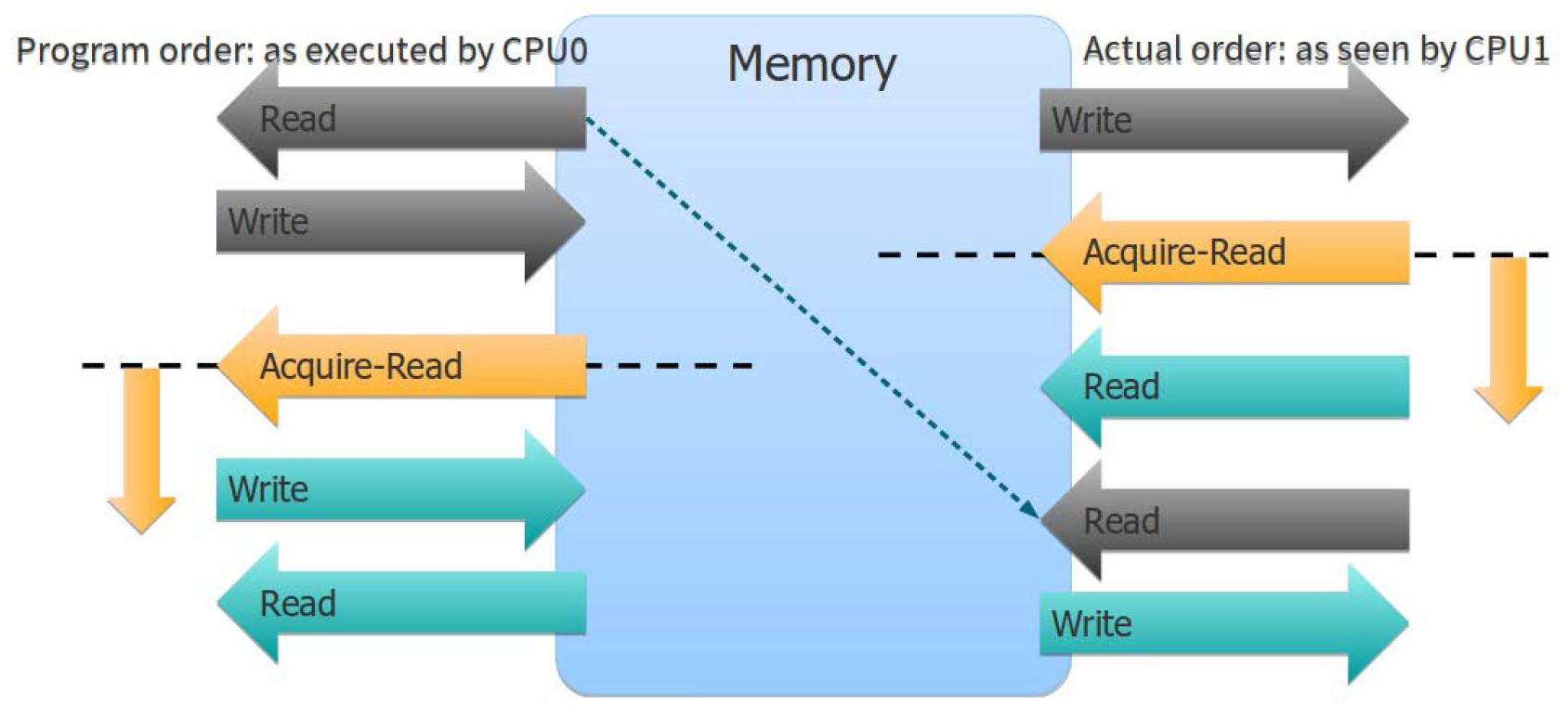
All operations executed after the barrier become visible to other threads after the barrier:
// transitivity.cpp
#include <atomic>
#include <iostream>
#include <thread>
#include <vector>
std::vector<int> mySharedWork;
std::atomic<bool> dataProduced(false);
std::atomic<bool> dataConsumed(false);
void dataProducer(){
mySharedWork = {1,0,3};
dataProduced.store(true, std::memory_order_release);
}
void deliveryBoy(){
while(!dataProduced.load(std::memory_order_acquire)){}
dataConsumed.store(true, std::memory_order_release);
}
void dataConsumer(){
while(!dataConsumed.load(std::memory_order_acquire)){}
mySharedWork[1] = 2;
}
int main(){
std::cout << std::endl;
std::thread t1(dataConsumer);
std::thread t2(deliveryBoy);
std::thread t3(dataProducer);
t1.join();
t2.join();
t3.join();
for (auto v: mySharedWork){
std::cout << v << " ";
}
std::cout << "\n\n";
}

The Typical Misunderstanding
// acquireReleaseWithWaiting.cpp
#include <atomic>
#include <iostream>
#include <thread>
#include <vector>
std::vector<int> mySharedWork;
std::atomic<bool> dataProduced(false);
void dataProducer(){
mySharedWork = {1, 0, 3};
dataProduced.store(true, std::memory_order_release);
}
void dataConsumer(){
while( !dataProduced.load(std::memory_order_acquire) );
mySharedWork[1] = 2;
}
int main(){
std::cout << std::endl;
std::thread t1(dataConsumer);
std::thread t2(dataProducer);
t1.join();
t2.join();
for (auto v: mySharedWork){
std::cout << v << " ";
}
std::cout << "\n\n";
}
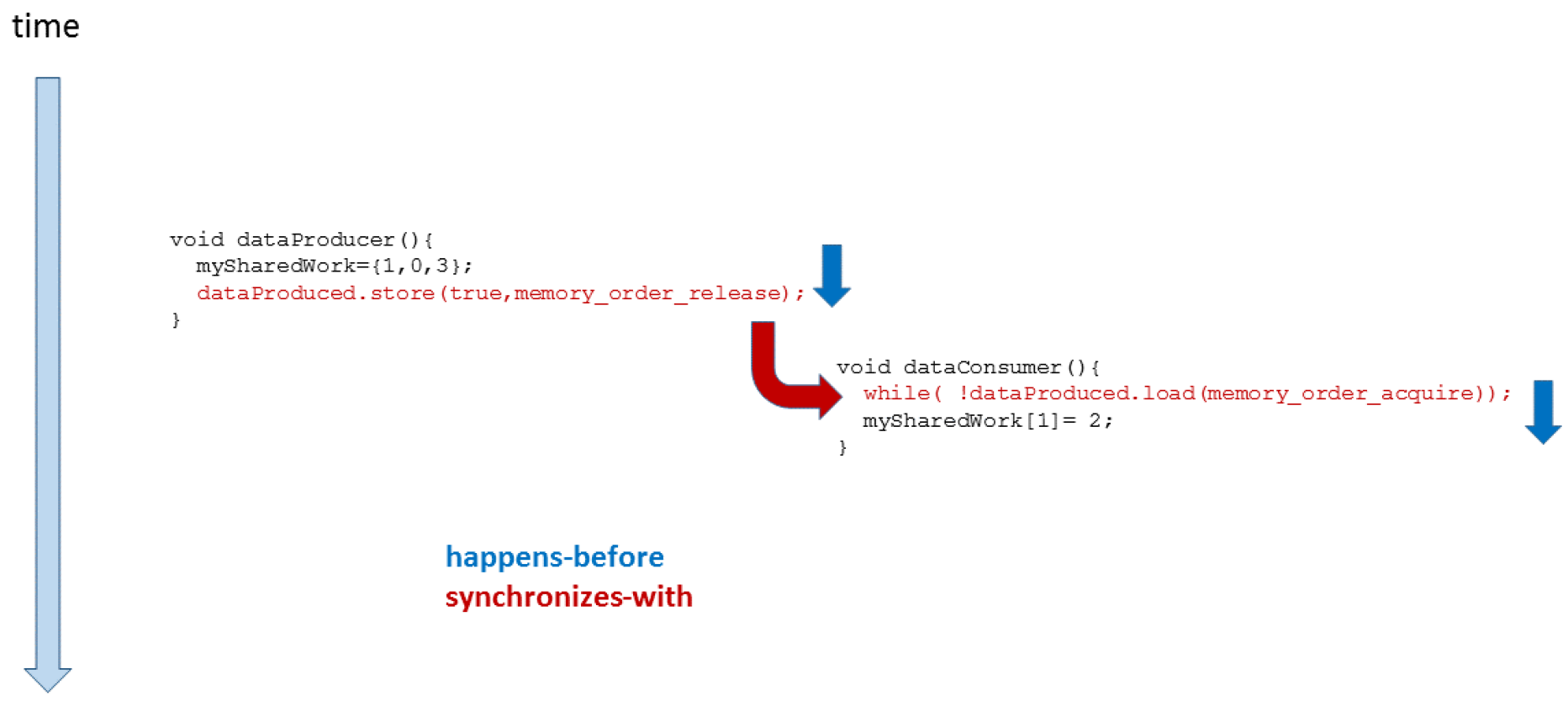
What happens if the consumer thread t1 doesn’t wait for the producer thread t2?
//...
void dataConsumer(){
dataProduced.load(std::memory_order_acquire);
mySharedWork[1] = 2;
}
//...

The program has undefined behaviour because there is a data race on the variable mySharedWork. dataProduced.store(true, std::memory_order_release) synchronizes-with dataProduced.load(std::memory_order_acquire). But it doesn’t mean the acquire operation waits for the release operation.
synchronizes-with in here means if dataProduced.store(true, std::memory_order_release) happens-before dataProduced.load(std::memory_order_acquire), then all visible effects of the operations before dataProduced.store(true, std::memory_order_release) are visible after dataProduced.load(std::memory_order_acquire). The key is the word “if”.
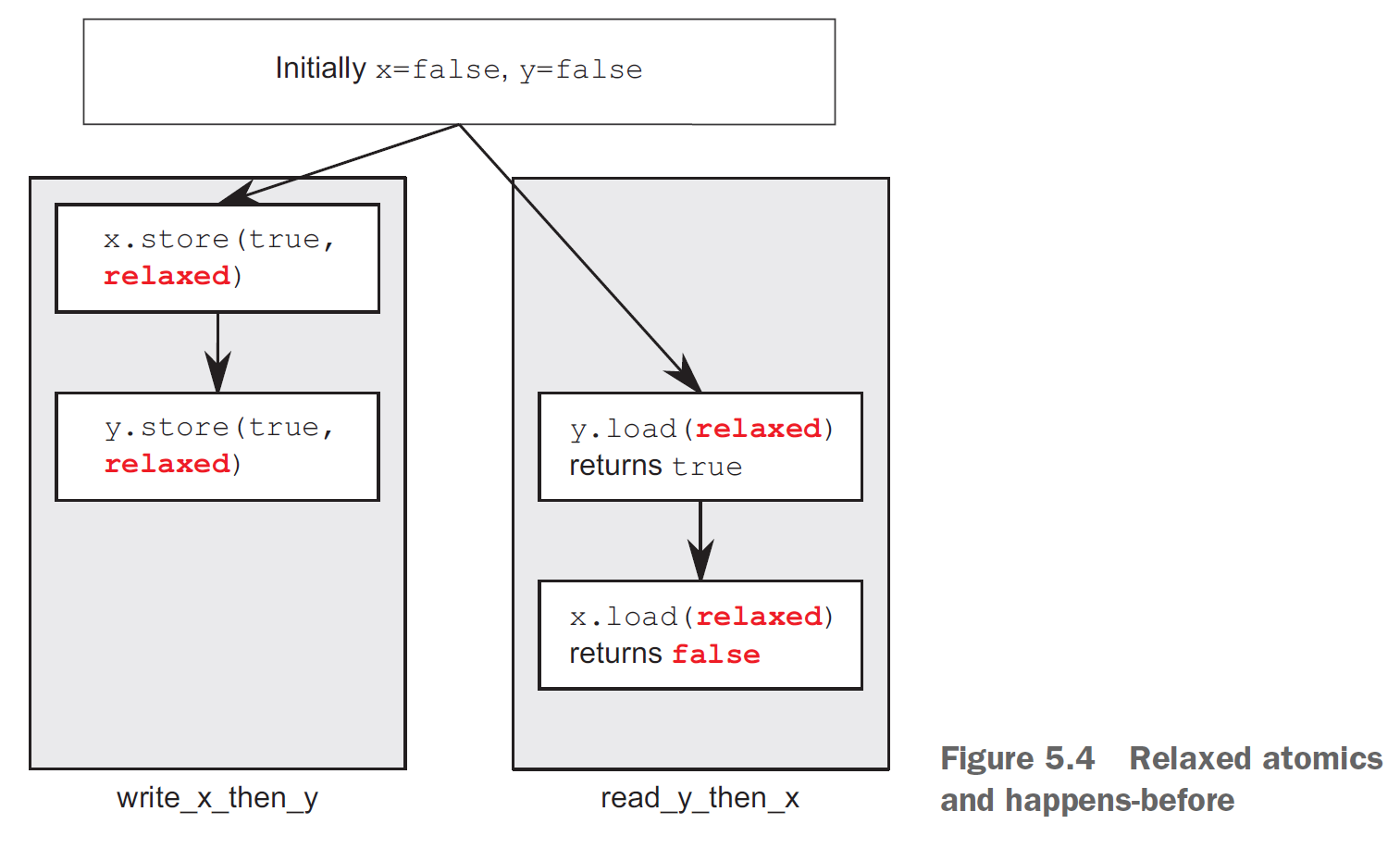
Relaxed
The relaxed semantic is the weakest of all memory models and only guarantees the modification order of atomics. This means all modifications on an atomic happen in some particular total order. It is quite easy:
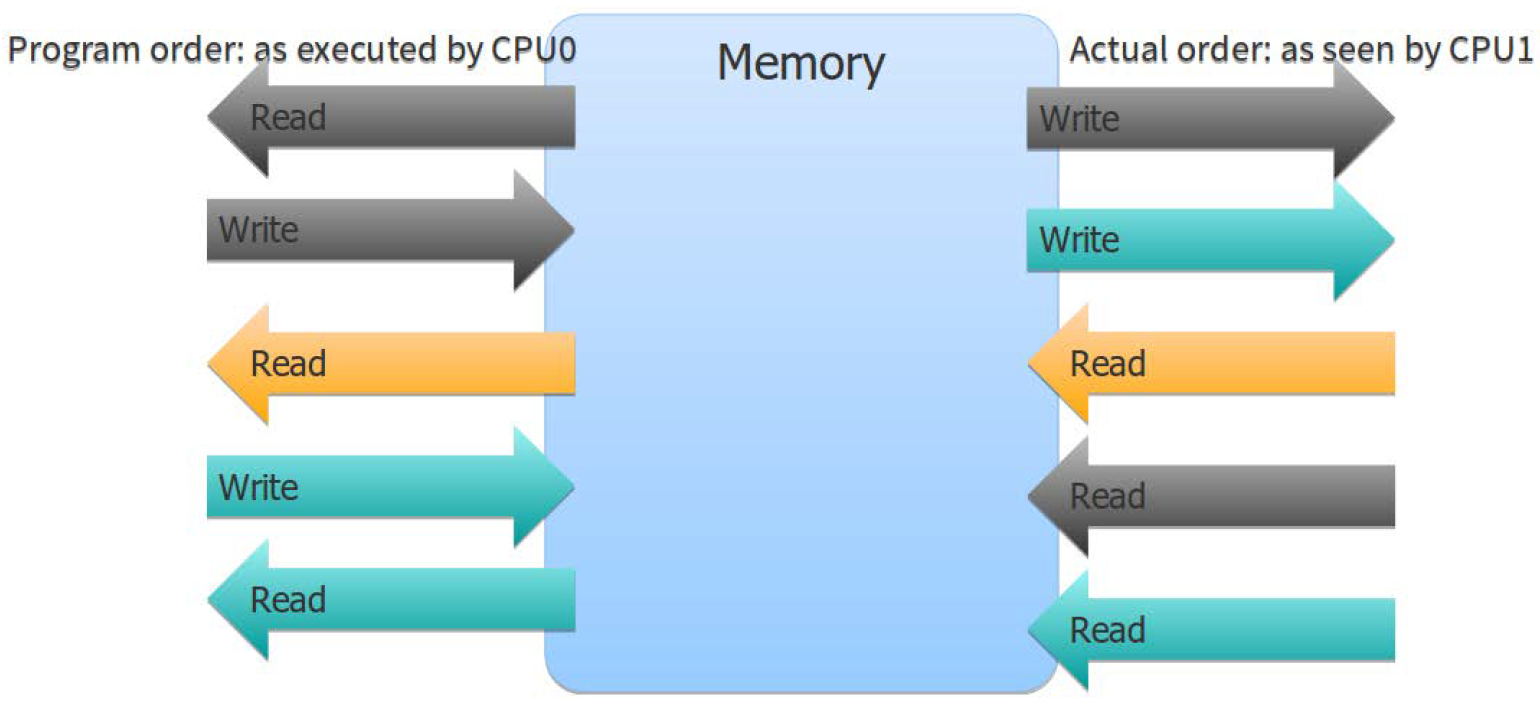
No synchronisation and ordering constraints. The only requirement is that accesses to a single atomic variable from the same thread can’t be reordered
#include <atomic>
#include <thread>
#include <assert.h>
std::atomic<bool> x,y;
std::atomic<int> z;
void write_x_then_y()
{
x.store(true,std::memory_order_relaxed);
y.store(true,std::memory_order_relaxed);
}
void read_y_then_x()
{
while(!y.load(std::memory_order_relaxed));
if(x.load(std::memory_order_relaxed))
++z;
}
int main()
{
x=false;
y=false;
z=0;
std::thread a(write_x_then_y);
std::thread b(read_y_then_x);
a.join();
b.join();
assert(z.load()!=0);
}
This time the assert can fire. x and y are different variables, so there are no ordering guarantees relating to the visibility of values arising from operations on each.
To understand how this works, imagine that each variable is a man in a cubicle with a notepad. On his notepad is a list of values. You can phone him and ask him to give you a value, or you can tell him to write down a new value. If you tell him to write down a new value, he writes it at the bottom of the list. If you ask him for a value, he reads you a number from the list.
The first time you talk to this man, if you ask him for a value, he may give you any value from the list he has on his pad at the time. If you then ask him for another value, he may give you the same one again or a value from farther down the list. He’ll never give you a value from farther up the list. If you tell him to write down a number and then subsequently ask him for a value, he’ll give you either the number you told him to write down or a number below that on the list.
“I strongly recommend avoiding relaxed atomic operations unless they are absolutely necessary, and even then using them only with extreme caution.”
-- Anthony Williams
A typical example of an atomic operation, in which the sequence of operations doesn’t matter, is a counter.
#include <vector>
#include <iostream>
#include <thread>
#include <atomic>
std::atomic<int> count = {0};
void add()
{
for (int n = 0; n < 1000; ++n) {
count.fetch_add(1, std::memory_order_relaxed);
}
}
int main()
{
std::vector<std::thread> v;
for(int n = 0; n < 10; ++n) {
v.emplace_back(add);
}
for(auto& t : v) {
t.join();
}
std::cout << "Final counter value is " << count << '\n';
}
std::memory_order_consume
std::memory_order_consume is the most legendary of the six memory orderings. That is for two reasons: first, it is extremely hard to understand and second - and this may change in the future - no compiler supports it currently.
The specification of release-consume ordering is being revised, and the use of memory_order_consume is temporarily discouraged
– since c++17 from cppreference
Memory Order Guarantees of a Mutex
Speaking of locks, what memory order guarantees do they give?
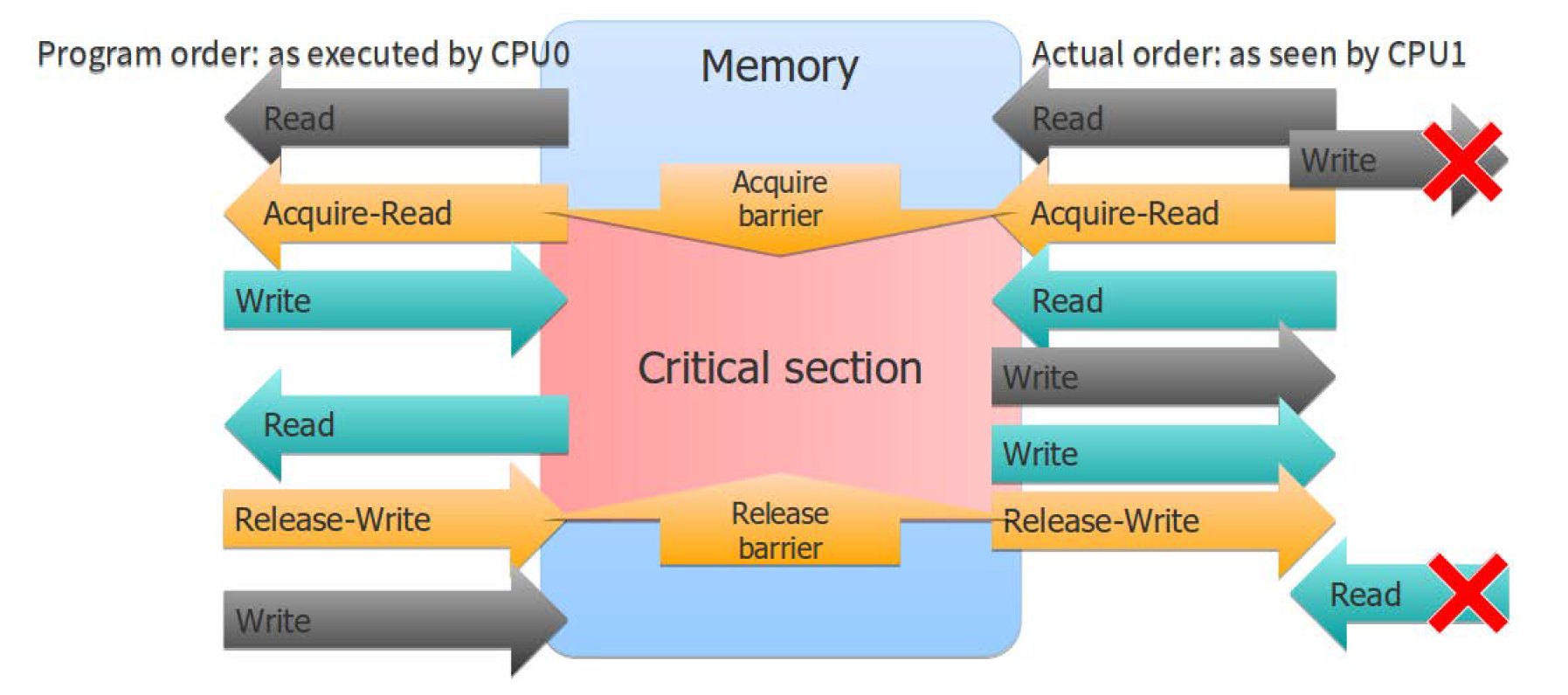
The mutexes have (at least) two atomic operations inside. Locking the mutex is an equivalent of a read operation with the acquire memory order (which explains the name: this is the memory order we use when we acquire the lock). The operation creates a half-barrier any operation executed earlier can be seen after the barrier, but any operation executed after the lock is acquired cannot be observed earlier. When we unlock the mutex or release the lock, the release memory order is guaranteed. Any operation executed before this barrier will become visible before the barrier. You can see that the pair of barriers, acquire and release, act as borders for the section of the code sandwiched between them. This is known as the critical section: any operation executed inside the critical section, that is, executed while the thread was holding the lock, will become visible to any other thread when it enters the critical section.
For producer-consumer example, we now can explain why we use atomic for counter is enough to write correct program.
std::atomic<size_t> N; // Count of initialized objects
T* buffer; // Only [0]…[N-1] are initialized
// … Producer …
{
new (buffer + N) T( … arguments … );
++N; // Atomic, no need for locks
}
// … Consumer …
for (size_t i = 0; keep_consuming(); ++i) {
while (N <= i) {}; // Atomic read
consume(buffer[i]);
}
//--------------------------------------------------------------
// which is equivalent to the folowing
new (buffer + N) T( … arguments … );
++N;
n = N;
consume(buffer[N]);
All operations executed by the producer to construct the Nth object are done before the producer enters the critical section. They will be visible to the consumer before it leaves its critical section and begins consuming the Nth object.
(If you think even
atomicis overkill for locking, and you want to reduce to half-barrier or others. You have to prove it by performance measurements, and only then can you reduce the guarantees to be just the ones you need.)