Vectorization: FLOPs for free
A note of Parallel and High Performance Computing.
依照實行的難易度,CPU平行化常用的技巧依序為:
- Vectorization: 利用現代CPU中的矢量處理器(AVX512, SSE4…)或SIMD單元。
- Multi-core and threading: 將工作分配到CPU中的多個處理核心。
- Distributed memory: 分布式內存計算涉及使用多個計算節點或計算機共同處理一個共同的任務。每個節點都有自己的內存,節點之間的通信通常通過消息傳遞完成。這種方法在高性能計算(HPC)環境中很常見,其中需要大規模的並行處理。
以下先介紹Vectorization。
SIMD Overview
Hardware Instruction Set for Vectorization
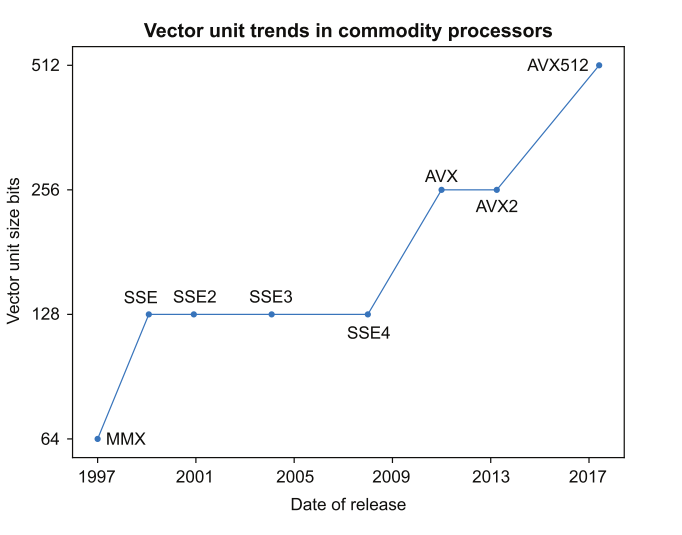 The appearance of vector unit hardware for commodity has slowly grow over the years.
The appearance of vector unit hardware for commodity has slowly grow over the years.
- 大部分的編譯器預設產生SSE2指令集的程式。
- AVX512在2017之後成為主流。
- 盡可能在最先進的CPU上使用最新版本的Compiler,以及合理地使用最先進的指令集。
Vectorization Methods
使用上的難易度由簡至深:
- Optimized libraries
- Auto-vectorization
- Hints to the compiler
- Vector intrinsics
- Assembler instructions
Optimized libraries
如Sparse Solvers、OpenBLAS、Intel的OneAPI MPI MKL等。
Auto-vectorization
因為簡單所以常作為Coding時的優先選擇。在C裡使用restrict或C++的__restrict、_restrict_。
#include <stdio.h>
#include "timer.h"
#define NTIMES 16
// large enough to force into main memory
#define STREAM_ARRAY_SIZE 80000000
static double a[STREAM_ARRAY_SIZE], b[STREAM_ARRAY_SIZE], c[STREAM_ARRAY_SIZE];
int main(int argc, char *argv[]){
struct timespec tstart;
// initializing data and arrays
double scalar = 3.0, time_sum = 0.0;
for (int i=0; i<STREAM_ARRAY_SIZE; i++) {
a[i] = 1.0;
b[i] = 2.0;
}
for (int k=0; k<NTIMES; k++){
cpu_timer_start(&tstart);
// stream triad loop
for (int i=0; i<STREAM_ARRAY_SIZE; i++){
c[i] = a[i] + scalar*b[i];
}
time_sum += cpu_timer_stop(tstart);
// to keep the compiler from optimizing out the loop
c[1] = c[2];
}
printf("Average runtime is %lf msecs\n", time_sum/NTIMES);
}